Modelos de branches
Tener un proyecto de desarrollo en marcha requiere de varias decisiones: qué lenguaje (o lenguajes) de programación se va/n a usar, cuáles van a ser los frameworks o librerías más relevantes (lo que incluye decidir si el desarrollo se va a estructurar de acuerdo a un framework o librería, o va a ser más “libre” usando librerías de más bajo nivel), qué forma va a a tener la API si es un backend, cómo se va a empaquetar el producto (p.ej. si se va a hacer un gran backend, o más bien se van a definir pequeños microservicios) y algunas más.
Obviamente, las decisiones no son independientes entre sí: si elijo usar SpringBoot como framework de backend, eso descarta la posibilidad de usar p.ej. Python como lenguaje.
Entre estas decisiones, está la de cómo se va a trabajar con el repositorio de código. En particular, qué branches se van a definir y cómo se van a usar.
¿Pusheamos todes en el mismo branch, y marcamos cada release con un tag? Caso contrario, ¿definimos un branch por tarea, o mejor un branch por persona? Cuando se termina algo ¿en qué branch se integra?
Un modelo de branches (o estrategia de branches / política de branches / workflow / flujo de trabajo) no es más (ni menos) que la suma de estas decisiones … más la meta-decisión de respetar las decisiones que se tomaron, claro.
Las decisiones sobre el modelo de branches a utilizar, también van a estar relacionadas con otras características que se definan para el proyecto.
En particular, la frecuencia con la que se quieran liberar releases, y el grado de automatización que se pueda organizar para esta tarea.
Otros factores que influyen sobre la definición de un modelo de branches, son el tamaño esperado del equipo de trabajo, y la criticidad del proyecto (lo que implica -entre otras cosas- qué tan rápido hay que actuar cuando aparece un bug).
Un panorama en 2020
Hay algunas propuestas de modelos de branches muy difundidas, como gitflow y GitHub Flow, que se llaman parecido pero son distintos.
En el sitio de tutoriales de Atlassian hay una página sobre el tema bastante extensa.
La posibilidad de pensar en distintos modelos de branches viene de la mano de Git, que ofrece un manejo de branches mucho más sencillo que sus antecesores, en particular SVN.
Qué sigue
En esta página, vamos a ir introduciendo paulatinamente los branches que se describen en Gitflow. Algunos de ellos son tremendamente populares, más que Gitflow en sí.
Al final, vamos a incorporar algunos comentarios sobre GitHub flow.
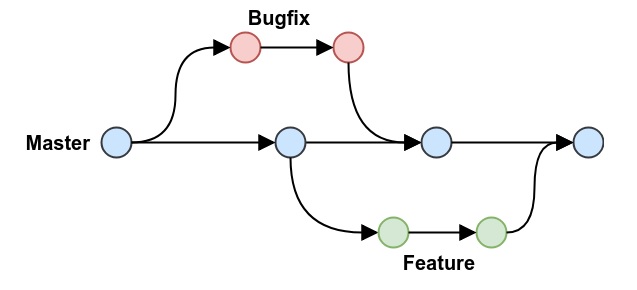
Modelo básico - master y develop
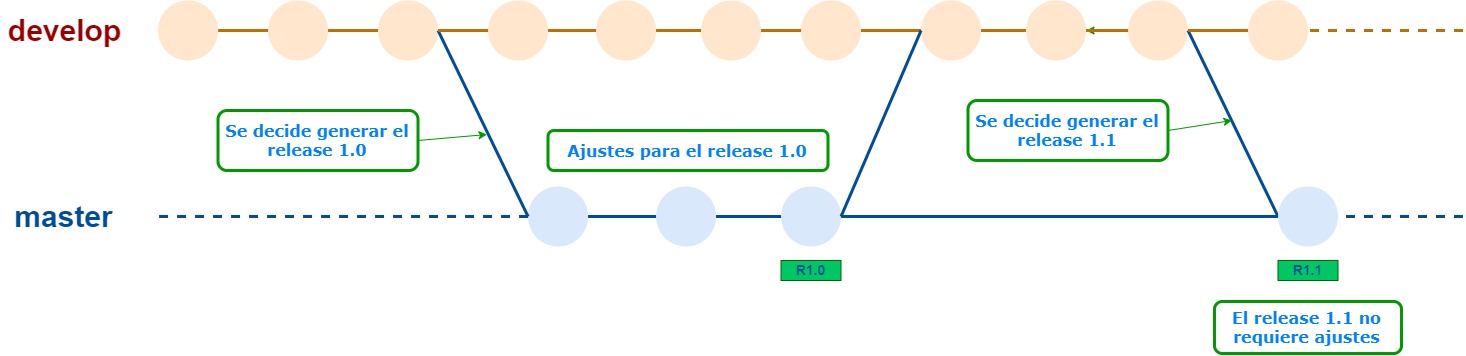
Empecemos con un modelo muy sencillo, que incluye solamente dos branches: master (o main), y develop.
En este modelo, todas las tareas se hacen sobre develop.
Cuando se decide armar un nuevo release, se mergea lo que esté en develop sobre master, y se empieza a probar el release candidato.
Si surgen bugs o agregados de último momento, se hacen directamente sobre master. Lo que se haga en develop después de que se hubiera “abierto” el release, va para el siguiente release. Lo que deba agregarse al release que se está preparando, va en master.
Cuando el release está listo, se agrega un tag en el commit correspondiente, que va a ser el tip de master en ese momento. Ese es el código que se va a deployar.
Al separar en un branch aparte la preparación del nuevo release, evitamos que incluya código que en realidad es para releases posteriores, y que puede venir con bugs que estarían “ensuciando” el release en preparación.
Si hubo commits agregados en master por bugs o agregados, conviene mergearlos sobre develop, para tener en ese branch todo el código a partir del cual se va a generar la siguiente versión.
Los dos branches, master y develop, son permanentes, o sea, siguen activos durante todo el desarrollo.
Esta imagen intenta mostrar el modelo que describimos recién.
Preguntas
Si al cerrar cada release mergeamos master sobre develop, entonces todo el código a partir del cual se genera el siguiente release va a estar en develop.
En este caso, cuando se decide preparar el siguiente release, en lugar de mergear develop sobre master ¿qué otra operación se puede hacer, que no es rebase?
Cuando se mergean los cambios que se hicieron en master sobre develop, ¿qué precaución conviene que tenga cada desarrollador?
¿Por qué los ajustes de cada release se hacen en master y no en develop?
Feature branches
Si hay varias personas trabajando sobre un mismo repositorio, aparece la probabilidad de que los cambios que hace una persona afecten el día-a-día del resto. Esto era común en la era pre-Git, y generaba retrasos importantes … o fomentaba poca interacción con el repositorio, con largos tiempos de sincronización después.
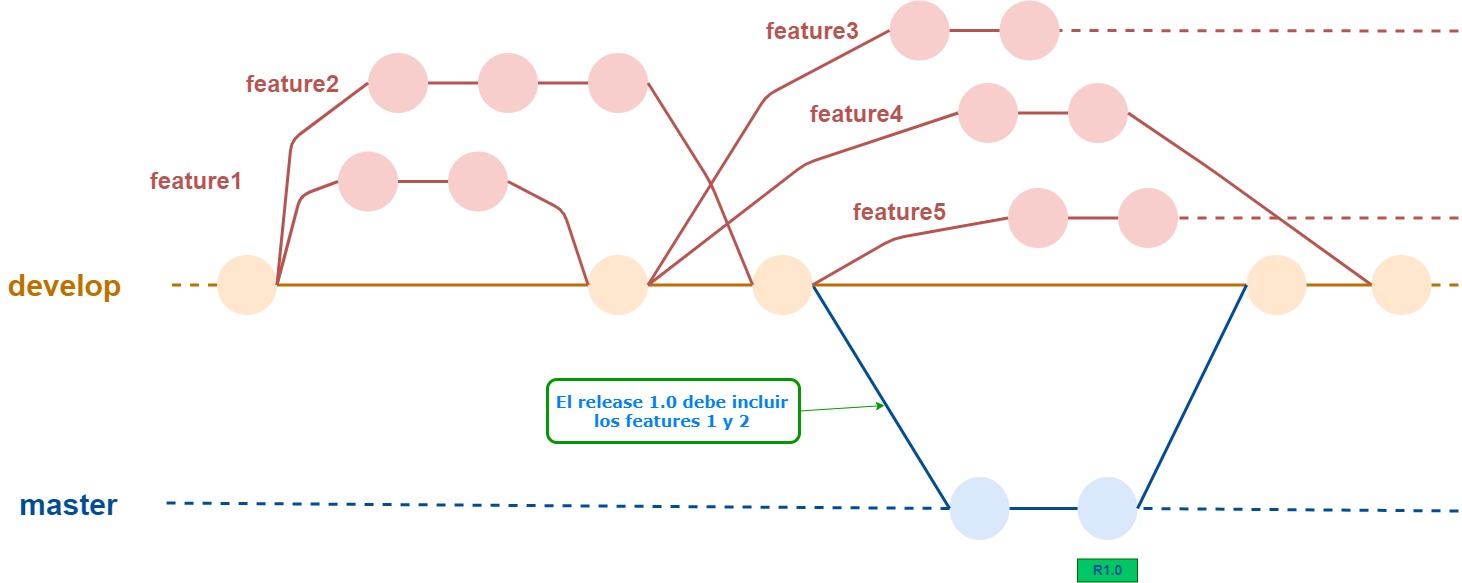
Para evitar estos problemas que surgen de estar tocando una misma base de código todos-todo-el-tiempo, surgió la idea de aislar el ambiente de trabajo de cada desarrollador (o grupo que está trabajando en lo mismo), definiendo un feature branch para cada tarea. Esta es una práctica muy extendida actualmente.
Por lo general, estos branches “salen” desde develop, y se integran sobre develop. Cuando están integrados en develop todos los features definidos para un release, se mergea sobre master y comienza el proceso de generación de release, como se describió antes.
La idea es que en develop esté integrado todo el código de las tareas finalizadas.
Al contrario de develop y master, los feature branches son temporales, o sea, tienen una vida limitada. Cuando se mergean sobre develop, se dejan de usar.
En este gráfico damos un ejemplo, en el cual los features 1, 2 y 4 están terminados, y por lo tanto esos branches ya no están activos. Los features 3 y 5 todavía se están desarrollando, por eso siguen activos.
Se pueden definir también branches para la corrección de bugs, puede ser un branch por bug, o definir un único branch para corregir varios bugs chicos que están relacionados. En cualquier caso, cuando se terminan de arreglar los bugs definidos, el branch se mergea sobre develop y se inactiva.
Notamos que la generación de cada nueva versión surge desde develop, que es donde se va integrando el trabajo a medida que se termina cada tarea.
Más preguntas
¿Cómo podemos manejar el caso de un feature que está terminado, pero que no queremos incluir en el siguiente release, que debe quedar para más adelante?
¿En qué caso podría tener sentido sacar un feature directamente desde master?
¿Con qué forma queda la historia de develop si se decide sistemáticamente hacer las integraciones de cada feature usando “squash and merge”?
¿Podría haber algún commit en develop que no sea un merge desde un feature o desde master?
¿Cómo acotar el riesgo de que un feature cuyo desarrollo lleva mucho tiempo, quede demasiado separado de develop, y después resulte muy difícil de mergear?
En el gráfico, el commit de develop en el que se integran los cambios hechos en master, tiene exactamente el mismo contenido que el del tag R1.0? ¿Podría no ser así, o sea que al mergear master sobre develop sea un merge que realmente integre dos líneas separadas de cambios? ¿En qué caso pasaría eso?
Release branches
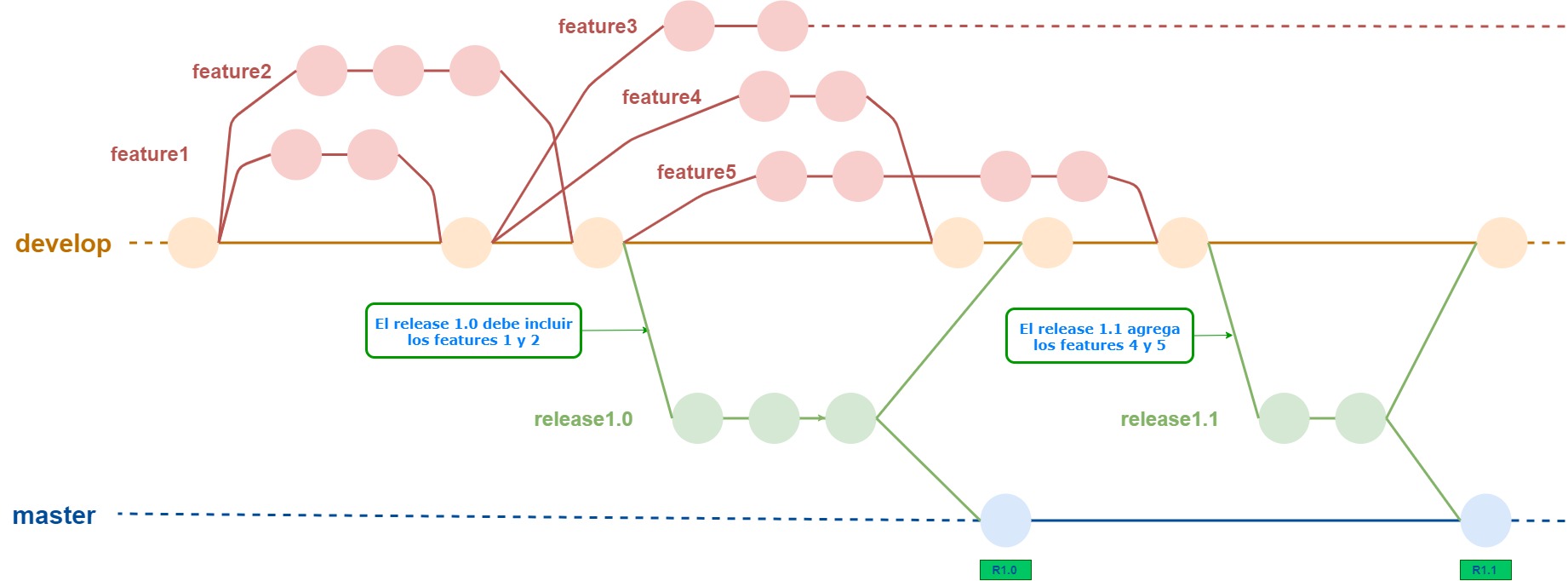
El siguiente paso de sofisticación consiste en separar el proceso de preparación de un release del branch master. Para esto se agregan a nuestro esquema los release branches, o sea, un nuevo branch para cada release.
Cuando están integrados los features definidos para un release, se crea el release branch correspondiente. Los ajustes se hacen en ese branch. Cuando el código está listo, se mergea el release branch a master, y también a develop (este último para tener todo integrado en develop).
Con este paso, logramos un objetivo que puede ser útil en la automatización de procesos: cada branch en master corresponde a un release. Por lo tanto, el agregado de un branch a master puede desencadenar los procesos de validación final y deploy en entornos productivos.
El esquema de trabajo queda como lo muestra este gráfico.
Otra preguntita
Los release branches ¿son temporales o son permanentes?
Hotfix branches
Como ya dijimos, para los bugs “que pueden esperar”, se abren feature branches, se integran sobre develop, y se incluirán en el siguiente release que se genere.
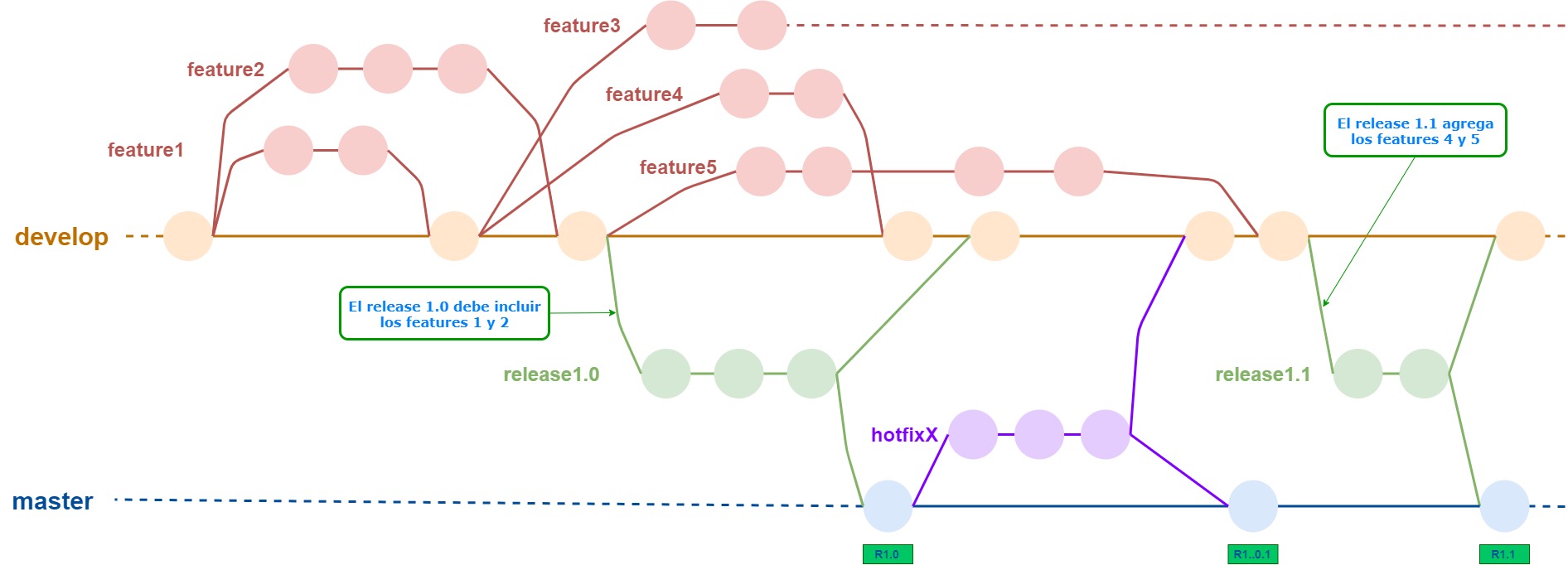
Ahora, ¿qué pasa si se encuentra un bug en producción y hay que arreglarlo urgente? Si lo arreglamos en master, podemos perder el principio de que “cada commit en master es un release”.
Para manejar esta situación, se agregan al escenario los hotfix branches. Estos salen de master, y vuelven a master
También se mergean a develop para que este siga siendo el branch que concentra todo el código.
Acertijo
Hay un caso en el cual, además de a master y a develop, conviene mergear un hotfix branch a un branch extra. ¿En qué caso, a qué branch?
Alternativas más ágiles - release vs. build
Lo que describimos hasta ahora, completo, corresponde a Gitflow, por lo menos como está definido en el artículo original.
Es un modelo elegante, cubre distintas variantes que son útiles, cierra.
Por otro lado, exige disciplina en el equipo de desarrollo. Y si hay mucha gente metiendo código, integrar se puede hacer complicado, porque para cada feature, el develop del momento de integrar puede ser bastante distinto del develop de cuando arrancó el feature.
Otro aspecto a tener en cuenta es que en muchas aplicaciones Web, deja de ser necesario tener un concepto fuerte de release, porque finalmente se despliega en un solo lado.
Todo esto motiva propuestas de modelos más livianos. Github Flow va por ese lado, incluye solamente un master que también juega de develop, o sea que de master sale lo que se deploya y también sirve como integración; más feature/bugfix branches, que se supone que tienen que ser de corta duración.
Esto va de la mano de pensar en builds que se generan en forma periódica (idealmente, todos los días), más que en releases. El build se genera, se aplican las validaciones pertinentes, y se lanza a producción.
Este esquema confía en que hay una infraestructura robusta de tests y validaciones automáticos, que ayuda a agilizar el proceso que va del editor de código a producción.
Va un gráfico, que es distinto de los otros porque está sacado del amplio archivo de la Web.
Ejercicio - producción de textos
Para practicar un poco la definición de modelos de branch, proponemos pensar cómo sería el modelo para un repo que se va a usar para la producción de un texto, que se va a escribir en forma colectiva.
El texto tiene distintas partes, que son redactadas por distintas personas. Al redactar una parte, conviene tener el texto completo, para mirarlo, y también para hacer pequeñas correcciones o agregados en otras partes.
Cuando se termina una tarea de redacción, tiene que pasar un corrector a revisarla. El corrector sugiere correcciones, que son ejecutadas por quienes hicieron la redacción. Las correcciones pueden dar lugar a debate entre quienes redactan y quienes corrigen. Una vez que una parte del texto está corregida, se integra y listo.
El texto puede tener distintas ediciones, las ediciones son lo que se publica. Tiene que ser fácil reconstruir el texto de una edición a partir del repo.
Pensar cuál podria ser un escenario de hotfix en este contexto.